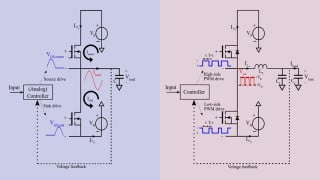
Facebook
Facebook Google
Google GitHub
GitHub Linkedin
Linkedin
This is wrong. An essential property of any algorithm is that it completes in a finite number of steps.An algorithm does NOT by definition have a finite number of steps.
The "algorithm" described by your flow chart cannot work for languages that have infinite number of words, and is therefore generally unsuitable to determine when L1 is a subset of L2. This is precisely the reason why the set theoretic gobbledygook is necessary, because it allows us to make definitive statements about sets, whether or not they are finite in size.
I happen to have the first edition of that book on my shelf and, unless it's scope has changed drastically, it's focus is on practical algorithms. Such a book will be of no use to the OP's current inquiries, which are squarely in the theoretical realm.Barring that, there's likely something already here_ your question's already been done by some developer:
Title: Algorithms in C, 3rd Ed. [Parts 1-4, Fundamentals, Data Structures, Sorting, Searching]
Author: Robert Sedgewick
ISBN: 0-201-31452-5